
Recommender engines are machine learning systems that facilitate a quick discovery of new products and services that might be of great interest.
In this era of e-commerce and several competing online services, one cannot but feel the impact of product recommendations in one’s day-to-day life. Every time we shop online, an underlying recommendation system guides us towards the most likely product that might be of interest to users. Such systems are generally grouped into two main categories: collaborative filtering and content-based systems. The later approach was adopted in this project. The system, developed in python, was integrated into a web app and subsequently deployed to Heroku.
Book-crossing data:
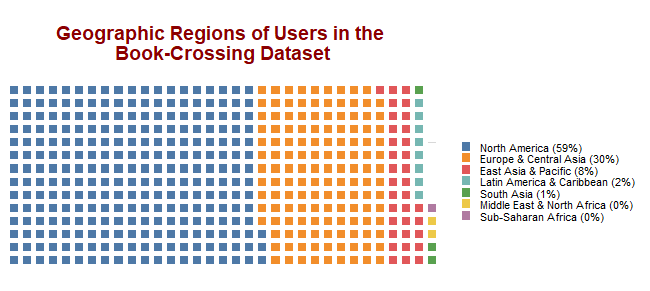
The data used for this project was adapted from the book-crossing dataset available here. The data was originally collected by Cai-Nicolas Ziegler in a 4-week crawl (August / September 2004) from the Book-Crossing community. It contains a total of 278,858 users (anonymized but with demographic information) providing 1,149,780 ratings (explicit / implicit) and about 271,379 books. More details about the dataset are available here. The final data for analysis was obtained after a thorough cleansing of the original dataset. These include checking for missing data points, wrong variable types and many more. To make things simple, we compressed the three separate datasets into one, with an inner joins of the relevant variables, bringing the total number of row entries to 32183. The demographic information of all users in the original dataset is shown in the figure below. As observed, greater number of users come from North American and Europe. These respectively account for about 60 and 30 per cent of all users.
Recommender Engine
As already mentioned, a content-based filtering system that depends on item-to-item similarity and the user’s explicit preferences was developed. Three important concepts that went into building such a system include Vectors, TF-IDF and Cosine Similarity. Texts or words were first converted into vectors and represented in a vector space model. The TF-IDF, a short for Term Frequency and Inverse Document Frequency was used to evaluate the importance of words in the corpus generated from the dataset. Cosine similarity was subsequently employed to measure the degree of similarity of all the items represented in a vector. Recommendations were thereafter made based on the scores of the different items in the document corpus. The python source files for the developed system are available in the project repository.

Web App
For a more user-friendly interface, the developed recommendation system was incorporated into a web app using streamlit. The app provides for selecting an item from a drop-down list, with a resultant list of similar items being generated. A table containing detailed information about the recommended items can as well be downloaded.
Final thoughts
Several organisations today employ recommender systems to make super-relevant recommendations of different products and services to customers. In this project, we developed a content-based recommendation system for items in the book-crossing dataset. It was further developed into a web app and subsequently deployed to Heroku.
You are welcome to contact DataXotic for questions or extra materials on this project.